字节跳动 EB 级 Iceberg 数据湖 机器学习应用、优化与数据服务支撑体系
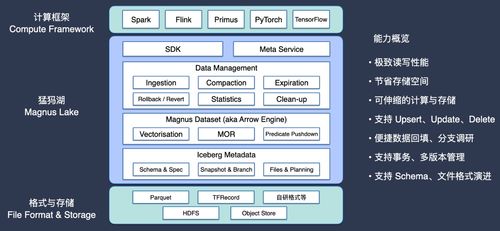
在数据驱动的时代,拥有海量数据并进行高效、智能的处理与分析,已成为科技巨头的核心竞争力。字节跳动,作为全球领先的内容与信息平台,其庞大的业务生态每日产生海量数据。为应对这一挑战,字节跳动构建并深度应用了 EB 级的 Apache Iceberg 数据湖架构,不仅为上层机器学习应用提供了坚实的数据基石,更在数据处理效率、存储成本优化及服务化支撑方面取得了显著成果。
一、Iceberg 数据湖:机器学习的数据基石
Apache Iceberg 作为一种开源的高性能表格式,解决了传统数据湖(如直接基于 HDFS)在数据一致性、 schema 演进、事务支持及高效查询上的诸多痛点。字节跳动将其作为核心数据湖表格式,构建了覆盖推荐、广告、搜索、内容安全等核心业务的统一数据底座。
对于机器学习而言,这一数据基石至关重要:
- 训练数据管理:机器学习模型的训练依赖于高质量、大规模的历史特征数据。Iceberg 的 ACID 事务保证确保了训练数据的一致性视图,避免了因数据更新而产生的“脏读”问题。其精细化的分区策略与隐式分区功能,使得数据工程师和算法工程师能够高效地定位和读取特定时间范围、特定用户群体或特定内容类型的训练样本。
- 特征工程与存储:特征仓库是机器学习系统的核心组件。利用 Iceberg 的 Schema 演进能力,可以安全、灵活地添加、删除或修改特征列,而无需重写整个历史数据表,这极大地支持了特征迭代与实验的敏捷性。Iceberg 对 Parquet、ORC 等高效列式存储格式的深度支持,使得特征数据的读取能够“按需取列”,大幅减少了 I/O 开销,加速了特征抽取流程。
- 线上/线下数据一致性:通过 Iceberg 管理的特征表,可以作为线下训练和线上推理共享的唯一数据源,确保了特征计算逻辑的一致性,有效规避了“训练-服务偏差”,提升了模型上线后的稳定性和效果。
二、核心优化实践:性能、成本与效率
面对 EB 级的数据规模,字节跳动对 Iceberg 数据湖进行了一系列深度优化:
- 数据布局优化:
- 智能分区与排序:结合业务查询模式(如频繁按天、按用户查询),设计高效的分区策略。在数据写入时引入 Z-Order 等多维排序技术,将相关联的数据(如同用户 ID 的行为记录)在物理上聚集存储,显著提升了查询性能,减少了扫描数据量。
- 小文件合并:流式数据持续写入极易产生海量小文件,严重拖累查询性能。字节跳动实现了自动化的后台小文件合并任务,根据文件大小、数量等阈值触发合并操作,保持数据湖的“健康度”。
- 查询加速与索引:
- 利用 Iceberg 的元数据(如 Manifest 文件)进行高效的剪枝,快速跳过不相关的数据分区和文件。
- 探索并集成布隆过滤器等二级索引,在文件级别进一步过滤无关数据行,为点查和特征回填等高并发查询场景提供支持。
- 存储成本管控:
- 数据生命周期管理 (DLM):自动化识别冷、热、温数据,并结合分层存储策略(如热数据存于高性能 SSD/内存,温数据存于标准 HDD,冷数据归档至对象存储)。Iceberg 的表格式抽象使得在不同存储介质间迁移数据对上层应用透明。
- 数据压缩与编码优化:针对不同类型的特征数据(如稀疏向量、枚举值),采用最合适的压缩算法和编码方式,在保证查询性能的同时最大化节约存储空间。
三、数据处理与存储支持服务:平台化与自助化
为使业务和算法团队能够高效、便捷地利用这一庞大的数据湖,字节跳动构建了强大的数据处理与存储支持服务体系:
- 统一数据服务平台:提供了从数据接入、ETL 开发、任务调度、质量监控到数据目录(Data Catalog)的一站式服务。用户可以通过 SQL 或可视化界面轻松地创建、管理 Iceberg 表,查询数据血缘,并订阅数据质量报告。
- 高性能查询引擎集成:数据湖的价值在于被高效查询。字节跳动将 Iceberg 与 Presto/Trino、Spark、Flink 以及内部自研的查询引擎深度集成,为不同的计算场景(即席分析、批处理、流批一体)提供统一的入口和最优的执行性能。
- 机器学习特征平台:基于 Iceberg 数据湖,构建了特征平台,提供特征定义、计算、存储、上线和监控的全链路能力。算法工程师可以自助完成特征注册、回溯计算、生成训练样本集,并将特征表一键发布为线上推理服务可访问的存储视图。
- 可观测性与治理:提供了全面的监控大盘,涵盖数据湖的存储量增长、文件分布、查询热度、任务耗时、成本消耗等维度。结合智能告警,帮助运维和开发团队快速发现和解决问题。通过数据治理工具管理元数据质量、数据安全与权限,确保数据湖的合规、有序运行。
###
字节跳动 EB 级 Iceberg 数据湖的实践表明,一个设计优良、深度优化的数据湖架构,是规模化机器学习应用取得成功的关键基础设施。它不仅解决了海量数据的存储与管理问题,更通过性能优化与成本管控,以及全面的平台化服务支持,将数据高效、可靠、经济地转化为机器学习模型的生产力,持续驱动着字节跳动各项业务的智能进化与创新。随着实时机器学习、大模型训练等场景的深入,对数据湖的实时性、吞吐量和跨域协同能力将提出更高要求,Iceberg 及其生态的持续演进值得期待。
如若转载,请注明出处:http://www.wqlyp.com/product/15.html
更新时间:2026-03-09 17:50:28