大模型训练数据的托管与治理 数据处理与存储支持服务的关键角色
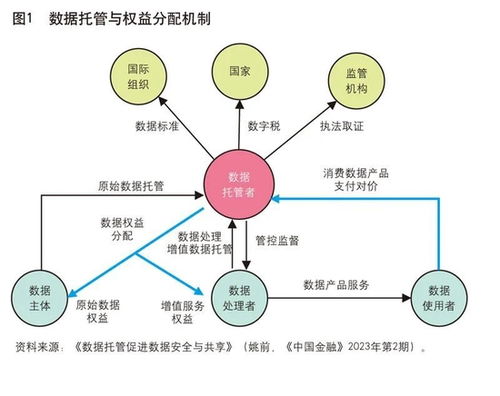
随着以ChatGPT为代表的生成式人工智能(AI)大模型在全球范围内掀起技术浪潮,训练数据的质量、规模与合规性已成为决定模型性能与可信度的核心要素。在这一背景下,训练数据的托管与治理,以及与之配套的数据处理和存储支持服务,正日益成为AI产业链中不可或缺的关键环节。
一、训练数据托管:安全与可访问性的基石
大模型的训练往往需要海量、多模态的数据集,这些数据可能包含文本、图像、音频、视频等多种形式,且来源广泛,涉及公开网络信息、专业数据库乃至特定授权内容。专业的数据托管服务旨在为这些宝贵的数据资产提供一个安全、可靠且高效的环境。
- 物理与逻辑安全:托管服务需构建多层次的安全防护体系,包括数据中心物理安全、网络入侵防御、数据加密传输与静态存储、严格的访问控制与身份认证机制,以防范数据泄露、篡改或丢失风险。
- 高可用与可扩展性:支持PB乃至EB级数据的存储,并能根据训练任务的需求弹性伸缩。高可用架构确保数据服务不间断,满足大规模分布式训练对数据高速、稳定读取的要求。
- 合规与跨境管理:在全球数据治理法规(如GDPR、中国的《数据安全法》、《个人信息保护法》)日趋严格的当下,托管服务需协助客户实现数据的合规存储与跨境流动管理,明确数据主权与管辖权。
二、数据治理:确保质量、合规与伦理
数据治理贯穿于数据生命周期的始终,其目标是在数据的获取、处理、使用过程中建立规范与秩序,是提升模型效果、控制风险的核心。
- 数据质量管控:建立数据清洗、去重、标注、质量评估的标准流程与工具链,确保输入模型的数据准确、一致、相关且无偏见,从源头提升模型输出的可靠性。
- 版权与知识产权管理:对训练数据源进行严格的版权审核与溯源,建立权利信息元数据体系,通过技术手段(如数字水印)与法律协议相结合,防范侵权风险,并为可能的权利金结算提供依据。
- 隐私与个人信息保护:采用去标识化、差分隐私、联邦学习等技术,在充分利用数据价值的有效保护个人隐私,满足“知情-同意”等法律原则。
- 内容安全与伦理审核:建立多层级的内容过滤与审查机制,剔除涉及违法、有害、歧视性或极端偏见的数据,引导模型符合人类伦理与社会价值观。
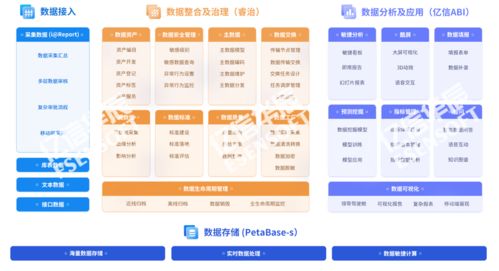
三、数据处理与存储支持服务:专业化的赋能体系
为应对上述托管与治理的复杂需求,一系列专业化的支持服务应运而生,它们构成了大模型数据基础设施的重要组成部分。
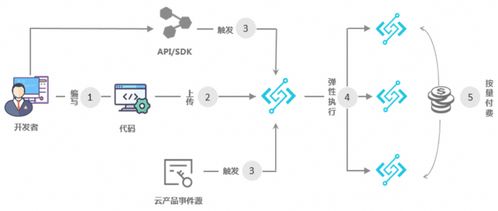
- 数据预处理与工程化服务:提供从原始数据采集、格式标准化、大规模标注(人工+智能辅助)、到构建可直接用于训练的精加工数据集的全套解决方案。这需要强大的算力平台与专业算法团队支持。
- 高性能存储解决方案:针对AI训练I/O密集型的特点,提供高性能文件存储(如支持POSIX接口的并行文件系统)、对象存储或混合存储方案,优化数据读取流水线,减少训练等待时间。
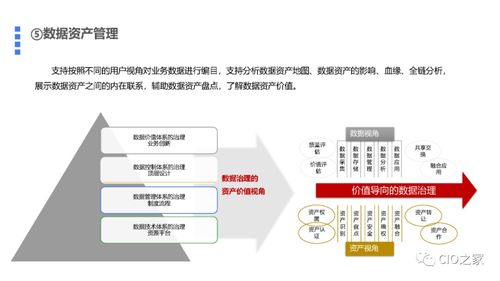
- 数据管理与协作平台:提供可视化的数据资产管理平台,实现数据目录、版本管理、血缘追踪、使用权限控制和协作共享功能,提升数据团队的工作效率与规范性。
- 合规与审计服务:提供数据合规性咨询、影响评估、审计日志记录与报告生成等服务,帮助客户应对监管要求,建立可信的数据使用记录。
四、未来展望:走向一体化与智能化
大模型训练数据的托管、治理与支持服务将呈现以下趋势:
- 一体化服务平台:将存储、计算、治理工具和安全能力深度集成,提供开箱即用、端到端的数据供应链解决方案。
- 智能化治理工具:更多地运用AI技术来管理AI数据,例如利用小模型自动进行数据质量检测、内容安全筛查、版权识别与隐私风险发现。
- 分布式与隐私计算融合:随着隐私保护要求提升,联邦学习、可信执行环境(TEE)等技术与数据托管基础设施将更紧密结合,实现“数据不动模型动”或“数据可用不可见”的安全训练范式。
- 标准化与生态构建:行业将推动数据格式、接口、权利描述、伦理评估等方面标准的建立,促进健康的数据流通与协作生态。
###
在AI大模型竞争日益激烈的今天,训练数据已成为核心战略资产。构建专业、安全、合规且高效的数据托管、治理与支持服务体系,不仅是技术实现的保障,更是确保AI创新行稳致远、赢得社会信任的基础性工程。对于企业和研究机构而言,前瞻性地布局和投资于这一领域的数据能力建设,将在未来的智能化竞争中占据至关重要的先机。
如若转载,请注明出处:http://www.wqlyp.com/product/18.html
更新时间:2026-03-07 21:54:58