Serverless架构在大规模数据处理与存储中的创新实践
Serverless架构在大规模数据处理与存储中的创新实践
一、引言
随着大数据时代的到来,企业和组织面临着海量数据的处理与存储挑战。传统的基于服务器的数据处理架构在应对大规模、高并发、弹性伸缩的场景时,往往面临资源利用率低、运维成本高、扩展性受限等问题。Serverless(无服务器)架构凭借其按需付费、自动扩缩容、免运维等核心特性,正逐渐成为大规模数据处理领域的重要技术范式。本文将深入探讨Serverless在大规模数据处理与存储支持服务中的实践应用、技术优势、挑战与未来发展趋势。
二、Serverless数据处理的核心模式
1. 事件驱动数据处理
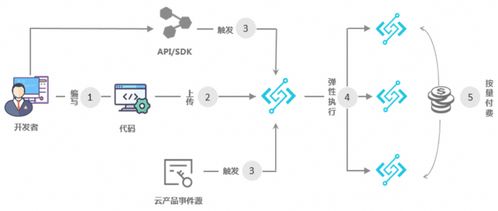
Serverless架构天然契合事件驱动模型。例如,当新的数据文件上传至对象存储(如AWS S3、阿里云OSS)时,可自动触发Serverless函数(如AWS Lambda、Azure Functions)执行数据清洗、格式转换或实时分析任务。这种模式特别适用于流式数据处理和ETL(提取、转换、加载)流水线,能够实现毫秒级响应和精准的资源匹配。
2. 批处理任务的无服务器化
对于定时或不定时的大规模批处理任务(如每日报表生成、历史数据归档),Serverless计算平台可自动分配资源并行执行任务。例如,AWS Step Functions结合Lambda可构建复杂的数据处理工作流,根据数据量动态调整并发实例数量,任务完成后自动释放资源,大幅降低成本。
3. 实时数据流水线
Serverless服务可与消息队列(如AWS Kinesis、Apache Kafka on Confluent Cloud)无缝集成,构建实时数据摄入与处理流水线。数据流经消息队列触发函数处理,结果可实时写入数据库或数据仓库,支撑实时监控、风险预警等场景。
三、Serverless存储支持服务的创新实践
1. 对象存储作为数据湖核心
以AWS S3、Google Cloud Storage为代表的对象存储服务,已成为Serverless数据湖的基石。它们提供近乎无限的存储容量、99.999999999%的持久性,并支持通过Serverless函数直接访问,无需预置存储服务器。结合数据目录服务(如AWS Glue Data Catalog),可实现数据的自动发现、元数据管理和查询优化。
- Serverless数据库与数据仓库
- Serverless数据库:如Amazon Aurora Serverless、Azure SQL Database Serverless,可根据查询负载自动扩缩容计算资源,在空闲时段甚至可缩至零,实现真正的按使用付费。
- Serverless数据仓库:如Google BigQuery、Amazon Redshift Serverless,突破了传统数据仓库的集群规划限制,可自动管理底层基础设施,支持PB级数据查询,并按扫描字节数计费。
3. 缓存层的Serverless化
如Amazon ElastiCache Serverless、Azure Cache for Redis,提供自动内存管理、自动故障转移和按需伸缩能力,作为数据处理流水线中的高性能缓存层,显著降低数据查询延迟。
四、技术优势与挑战
优势:
- 极致弹性与成本优化:资源按毫秒级粒度分配,业务高峰自动扩容,空闲时成本接近零,尤其适合处理波动性大的数据工作负载。
- 简化运维:基础设施管理完全由云厂商负责,团队可专注于业务逻辑开发,缩短迭代周期。
- 高可用与容错性:云平台内置多可用区部署和自动故障恢复机制,保障数据处理流水线的持续运行。
挑战与应对策略:
- 冷启动延迟:函数首次调用或长时间未调用后的初始化延迟可能影响实时性。可通过预置并发、保持函数活跃状态、优化依赖包体积等方式缓解。
- 状态管理与数据一致性:Serverless函数本质上是无状态的,复杂的数据处理流水线需要借助外部存储(如数据库、对象存储)或状态机服务(如AWS Step Functions)来管理状态和保证一致性。
- 调试与监控复杂性:分布式、短生命周期的函数使得调试和端到端跟踪更具挑战。需充分利用云平台提供的日志服务(如AWS CloudWatch Logs)、分布式追踪(如AWS X-Ray)和监控仪表板。
- 供应商锁定风险:深度依赖特定云厂商的Serverless服务可能导致迁移成本高昂。建议通过抽象业务逻辑层、采用多云兼容的框架(如Serverless Framework)来降低风险。
五、实践案例与最佳实践
1. 案例一:电商实时推荐系统
某电商平台使用API Gateway接收用户行为事件,触发Lambda函数进行实时特征计算,结果写入DynamoDB。Kinesis Data Streams持续摄入点击流数据,由Lambda进行聚合分析,更新用户画像于S3数据湖中。整个系统无需管理服务器,日均处理数十亿事件,成本仅为传统架构的30%。
2. 案例二:媒体内容处理流水线
视频平台用户上传原始视频至S3,触发Lambda生成多个分辨率的转码版本,并提取元数据存入Aurora Serverless。转码任务通过Step Functions协调,利用Lambda和Fargate(Serverless容器)混合处理,高峰时段自动扩展至上千并发任务。
- 最佳实践:
- 设计无状态函数:将状态外置至数据库或存储服务,确保函数可任意水平扩展。
- 实施细粒度监控:对函数执行时间、内存使用、错误率设置告警,并建立业务级指标(如数据处理吞吐量)。
- 优化数据访问模式:通过批处理读取、合理设置缓存、使用列式存储格式(如Parquet)来减少I/O开销和成本。
- 安全与合规:利用云平台的身份与访问管理(IAM)服务实施最小权限原则,对敏感数据进行加密(如使用AWS KMS),并确保数据处理符合GDPR等法规要求。
六、未来展望
随着边缘计算、人工智能与Serverless的融合,大规模数据处理将呈现以下趋势:
- 边缘Serverless数据处理:在靠近数据源的边缘节点运行轻量级函数,实现更低延迟的实时分析和响应,适用于物联网、车联网等场景。
- AI驱动的自动优化:云平台将利用机器学习预测工作负载,提前预热资源、优化函数分配策略,进一步降低冷启动影响和成本。
- 统一的数据处理编程模型:如Apache Spark on Serverless、Flink on Lambda等集成方案将更加成熟,允许开发者使用熟悉的大数据框架,底层则由Serverless平台自动管理资源。
- 跨云Serverless数据服务:多云和混合云环境下的Serverless数据流水线编排工具将应运而生,支持跨云数据迁移、联邦查询和统一治理。
七、
Serverless架构为大规模数据处理与存储带来了革命性的变革。通过将基础设施管理的复杂性转移给云平台,它使组织能够以更低的成本和更高的敏捷性应对数据洪流的挑战。尽管在状态管理、调试和供应商锁定等方面仍存在挑战,但随着技术的不断成熟和最佳实践的积累,Serverless正成为构建现代、高效、可扩展的数据处理系统的关键选择。对于希望在大数据领域保持竞争力的企业而言,拥抱Serverless不仅是技术升级,更是向数据驱动、精益运营转型的重要一步。
如若转载,请注明出处:http://www.wqlyp.com/product/20.html
更新时间:2026-03-07 01:10:02